 In my previous post for State of Digital I wrote about my ‘Three Pillars’ approach to SEO: Technology, Relevance, and Authority. Together these three pillars create a holistic view of SEO that should take all aspects of a website in to account. Additionally, the three pillars map to the three main processes in web search engines: crawling, indexing, and ranking.
In my previous post for State of Digital I wrote about my ‘Three Pillars’ approach to SEO: Technology, Relevance, and Authority. Together these three pillars create a holistic view of SEO that should take all aspects of a website in to account. Additionally, the three pillars map to the three main processes in web search engines: crawling, indexing, and ranking.
I want to elaborate further on each of the three pillars, starting with the first: technology.
The technological aspect of SEO is something many practitioners are, by their own admission, only passingly familiar with. It’s also one of the aspects of SEO that intrudes in the domain of web developers and server administrators, which means that for many marketing-focused SEOs it’s not something they can easily get their hands dirty with.
Yet it can be a tremendously important aspect of good SEO, especially for large-scale complicated websites. Whilst the average WordPress site won’t need a lot of technical SEO fixes applied to it (hopefully), large news publishers and enterprise-level ecommerce platforms are a different story altogether.
Why this is the case is something that becomes evident when you understand the purpose of technical SEO which, in my model, is crawl efficiency. For me the technology pillar of SEO is about making sure search engines can crawl your content as easily as possible, and crawl only the right content.
Crawl Efficiency
When the technological foundations of a website are suboptimal, the most common way this affects the site’s SEO is by causing inefficiencies in crawling. This is why good technical SEO is so fundamental: before a search engine can rank your content, it first needs to have crawled it.
A site’s underlying technology impacts, among many other things, the way pages are generated, the HTTP status codes that it serves, and the code it sends across the web to the crawler. These all influence how a web crawler engages with your website. Don’t assume that your site does these things correctly out of the box; many web developers know the ins and outs of their trade very well and know exactly what goes in to building a great user-focused website, but can be oblivious to how their site is served to web crawlers.
When it comes to technical SEO, the adage “focus on your users and SEO will take care of itself” is proven entirely erroneous. A website can be perfectly optimised for a great user experience, but the technology that powers it can make it impossible for search engines to come to grips with the site.
In my SEO audit checklists, there are over 35 distinct aspects of technical SEO I look for. Below I summarise three of the most important ones, and show how they lead to further investigations on a whole range of related technical issues.
Crawl Errors
When analysing a new website, the first place many SEOs will look (myself included) is the Crawl Errors report in Google Webmaster Tools. It still baffles me how often this report is neglected, as it provides such a wealth of data for SEOs to work with.
When something goes wrong with the crawling of your website, Google will tell you in the Crawl Errors report. This is first-line information straight from the horse’s mouth, so it’s something you’ll want to pay attention to. But the fact this data is automatically generated from Google’s toolset is also the reason we’ll want to analyse it in detail, and not just take it at face value. We need to interpret what it means for the website in question, so we can propose the most workable solution.

In the screenshot above we see more than 39,000 Not Found errors on a single website. This may look alarming at first glance, but we need to place that in the right context.
You’ll want to know how many pages the website actually has that you want Google to crawl and index. Many SEOs first look at the XML sitemap as a key indicator of how many indexable pages the site has:

It’s evident that we’re dealing with a pretty substantial website, and the 39k Not Found errors now seems a little less apocalyptic amidst a total of over 300k pages. Still, at over 11% of the site’s total pages the 39,000 Not Found errors presents a significant level of crawl inefficiency. Google will spend too much time crawling URLs that simply don’t exist.
But what about URLs that are not in the sitemap and which are discovered through regular web crawls? Never assume the sitemap is an exhaustive list of URLs on a site – I’ve yet to find an automatically generated XML sitemap that is 100% accurate and reliable.
So let’s look further and see how many pages on this site Google has actually indexed:

The plot thickens. We have 39k Not Found errors emerging from 329k URLs in the XML sitemap and the regular web crawl, which in turn has resulted in over 570k URLs in Google’s index. But this too doesn’t yet paint the entire picture: the back-end CMS that runs this website reports over 800k unique pages for Google to crawl and index.
So by analysing one single issue – crawl errors – we’ve ended up with four crucial data points: 39k Not Found errors, 329k URLs in the XML sitemap, 570k indexed URLs, and 800K unique indexable pages. The latter three will each result in additional issues being discovered, which leads me to the next aspect to investigate: the XML sitemap.
But before we move on, we need to recommend a fix for the Not Found errors. We’ll want to get the full list of crawlable URLs that result in a 404 Not Found error, which in this case Google Webmaster Tools cannot provide; you can only download the first 1000 URLs.
This is where SEO crawlers like Screaming Frog and DeepCrawl come in. Run a crawl on the site with your preferred tool and extract the list of discovered 404 Not Found URLs. For extra bonus points, run that list through a link analysis tool like Majestic to find the 404 errors that have inbound links, and prioritise these for fixing.
XML Sitemaps
No matter how well a website is structured and how easy it is to navigate to any page, I never assume the site doesn’t need an XML sitemap. Some SEO ranking correlation studies show a positive correlation between the presence of an XML sitemap and higher rankings, but this is likely not a direct causal effect; the presence of an (error-free) XML sitemap is a sign of a website that has been subjected to proper SEO efforts, where the sitemap is just one of many things the optimisers have addressed.
Nonetheless I always recommend having an error-free XML sitemap, because we know search engines use it to seed their crawlers. Including a URL in your XML sitemap doesn’t guarantee it’ll be indexed, but it certainly increases its chances, and it ensures that the bulk of your site’s crawl budget is used on the right pages.
Again, Google Webmaster Tools is the first place to start, specifically the Sitemaps report:
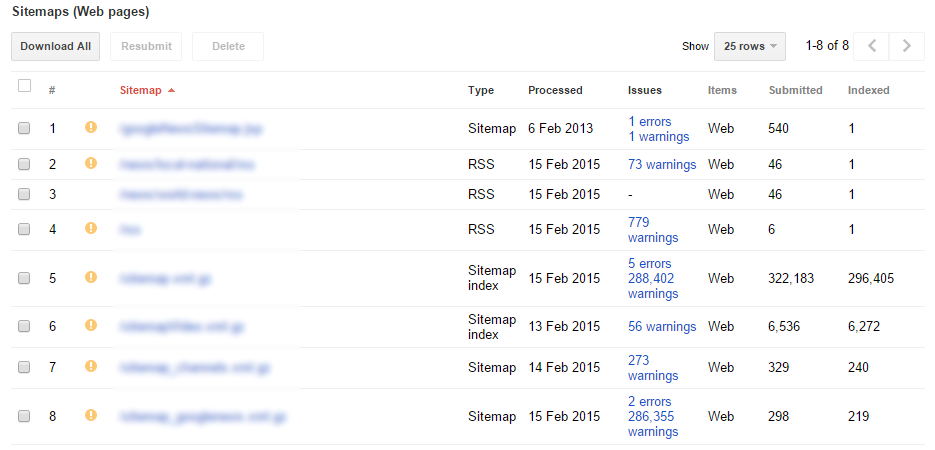
Here we see that every single sitemap submitted by this site has one or more errors. As this is an old website that has gone through many different iterations and upgrades, this is not unsurprising. Still, when we see a sitemap with 288,000 warnings, it seems obvious there’s a major issue at hand.
Fortunately Google Webmaster Tools provides more details about what errors exactly it finds in each of these sitemaps:

There are several issues with this sitemap, but the most important one is that it has thousands upon thousands of URLs that are blocked by robots.txt, preventing Google from crawling them.
Now because we have a number of earlier established data points, namely that out of 800k unique pages only 570k are actually in Google’s index, this number of 288k blocked URLs makes sense. It’s obvious that there is a bit of excessive robots.txt blocking going on that prevents Google from crawling and indexing the entire site.
We can then identify which robots.txt rule is the culprit. We take one of the example URLs provided in the sitemap errors report, and put that in the robots.txt tester in Webmaster Tools:

Instantly it’s obvious what the problem with the XML sitemap is: it includes URLs that belong to the separate iPad-optimised version of the site, which are not meant for Google’s web crawlers but that instead are intended for the website’s companion iPad app.
And by using the robots.txt tester we’re now also aware that the robots.txt file itself has issues: there are 18 errors reported in Webmaster Tools, which we’ll need to investigate further to see how that impacts on site crawling and indexing.
Load Speed
While discussing XML sitemaps above, I referenced ‘crawl budget‘. This is the concept that Google will only spend a certain amount of time crawling your website before it terminates the process and moves on to a different site.
It’s a perfectly logical idea, which is why I believe that it still applies today. After all, Google doesn’t want to waste endless CPU cycles on crawling infinite URL loops on poorly designed websites, so it makes sense to assign a time period to a web crawl before it expires.
Moreover, beyond the intuitive sensibility of crawl budgets, we see that when we optimise the ease with which a site can be crawled, the performance of that site in search results tends to improve. This all comes back to crawl efficiency; optimising how web crawlers interact with your website to ensure the right content is crawled and no time is wasted on the wrong URLs.
As crawl budget is a time-based metric, that means a site’s load speed is a factor. The faster a page can be loaded, the more pages Google can crawl before the crawl budget expires and the crawler process ends.
And, as we know, load speed is massively important for usability as well, so you tick off multiple boxes by addressing one technical SEO issue.
As before, we’ll want start with Webmaster Tools, specifically the Crawl Stats report:
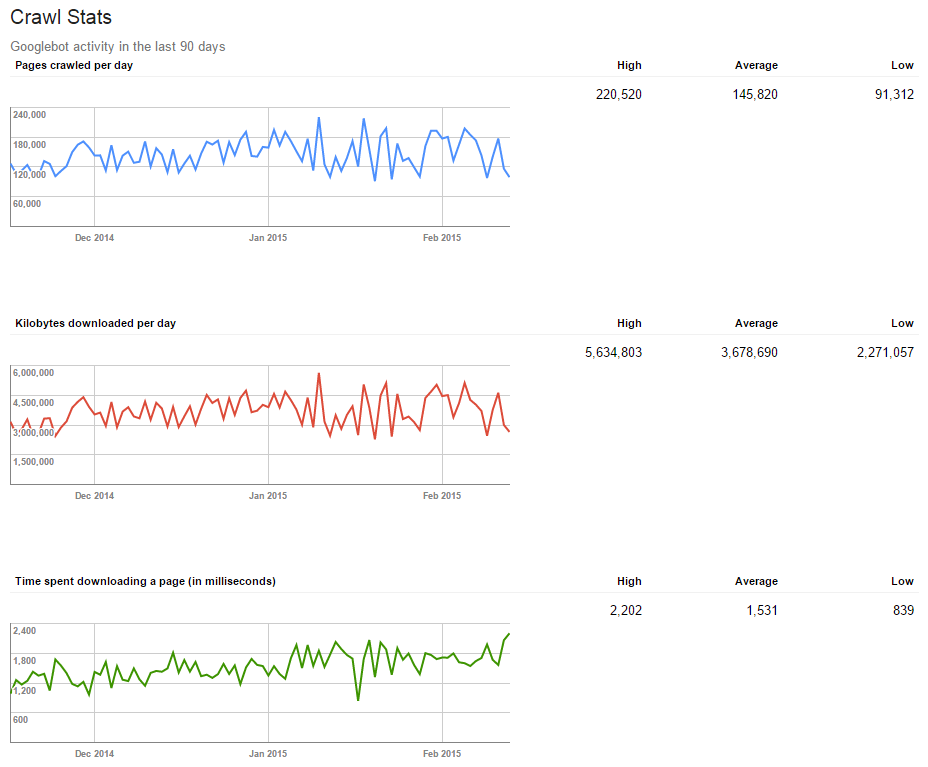
At first glance you’d think that these three graphs will give you all you need to know about the crawl budget Google has set aside for your website. You know how many pages Google crawls a day, how long each page takes to load, and how many kilobytes cross the ether for Google to load all these pages. A few back-of-a-napkin calculations will tell you that, using the reported average numbers, the average page is 25 kilobytes in size.
But 1.5 seconds load time for 25KB seems a bit sluggish, and even a cursory glance at the website will reveal that 25KB is a grossly inaccurate number. So it seems that at last we’ve exhausted the usefulness of Google Webmaster Tools, at least when it comes to load speed issues.
We can turn to Google Analytics next and see what that says about the site’s load speed:

There we go; a much better view of the average load speed, based on a statistically significant sample size as well (over 44k pages). The average load speed is a whopping 24 seconds. Definitely something worth addressing; not just for search engines, but also for users that have to wait nearly half a minute for a page to finish loading. That might be perfectly fine in the old days of 2400 baud modems, but it’s simply unacceptable these days.
But this report doesn’t tell us what the actual problems are. We only know that the average load speed is too slow. We need to provide actionable recommendations, so we need to dig a bit deeper.
There are many different load speed measurement tools that all do a decent job, but my favourite is without a doubt WebPageTest.org. It allows you do select a nearby geographic location and a browser version, so that you get an accurate reflection of how your users’ browsers will load your website.
What I like most about WebPageTest.org is the visual waterfall view it provides, showing you exactly where the bottlenecks are:
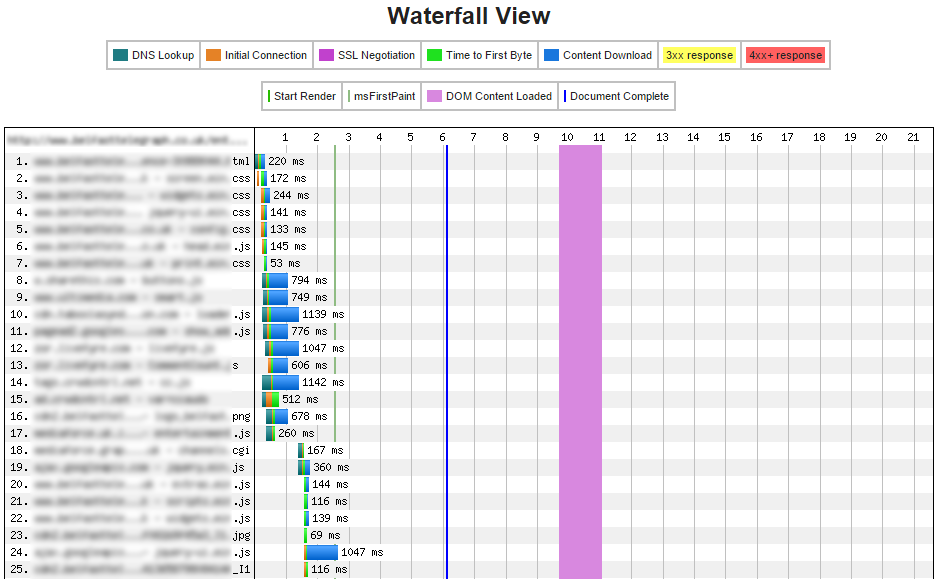
The screenshot above is just the first slice of the total waterfall view, and immediately we can see a number of potential issues. There are a large number of JS and CSS files being downloaded, and some take over a full second to load. The rest of the waterfall view makes for equally grim reading, with load times on dozens of JS and image files well over the one second mark.
Then there are a number of external plugins and advertising platforms being loaded, which further extend the load speed, until the page finally completes after 21 seconds. This is not far off the 24 second average reported in Google Analytics.
It’s blatantly obvious something needs to be done to fix this, and the waterfall view will give you a number of clear recommendations to make, such as minimising JS and CSS and using smaller images. As a secondary data set you can use Google’s PageSpeed Insights for further recommendations:

When it comes to communicating my load speed recommendations to the client I definitely prefer WebPageTest.org, as the waterfall view is such a great way to visualise the loading process and identify pain points.
Down The Rabbit Hole
At this stage we’ve only ticked off three of the 35 technical SEO aspects on my audit checklist, but already we’ve identified a number of additional issues relating to index levels and robots.txt blocking. As we go on through the audit checklist we’ll find more and more issues to address, each of which will need to be analysed in detail so that we can provide the most effective recommendation that will address the problem.
In the end, technical SEO for me boils down to making sure your site can be crawled as efficiently as possible. Once you’re confident of that, you can move on to the next stage: what search engines do with the pages they’ve crawled.
The indexing process is what allows search engines to make sense of what they find, and that’s where my Relevance pillar comes in, which will be the topic of my next article.
Post from Barry Adams