Optimizing a website for your target audience can be tricky. Optimizing a large website for your target audience can be even trickier. Since the last article, DeepCrawl recently launched a significant update to a brand new crawler which is a lot faster and there are now a bunch of new reports available.
Below are 46 new and updated tips and tricks to optimise the search signals for your websites in Google’s organic search.
Spend more time making recommendations and changes
(and less time trawling through data)
1. Crawl MASSIVE Sites
If you have a really large website with millions of pages you can scan unlimited amounts with the custom setting – so long as you have enough credits in your account!
How To Do It:
- From the crawl limits in step 3 of crawl set up, adjust the crawl limit to suit your target domain’s total URLs
- Crawl up to 10 million using pre-fabricated options from the dropdown menu
- For a custom crawl, select “custom” from the dropdown menu and adjust max URLs and crawl depth to suit your reporting needs
![01-crawl-massive-sites]()
2. Compare Previous Crawls
Built into DeepCrawl is the ability to compare your current crawl with the most recent crawl, this is useful for tracking changes as they are implemented, and for providing rich data for your organization to show the (hopefully positive) impacts of your SEO changes on the site. You’ll also be able to see all of your previous crawls as well.
How To Do It:
- On step 4 of your crawl set up, you can select to compare your new crawl to a previous one
![02-compare-previous-crawls]()
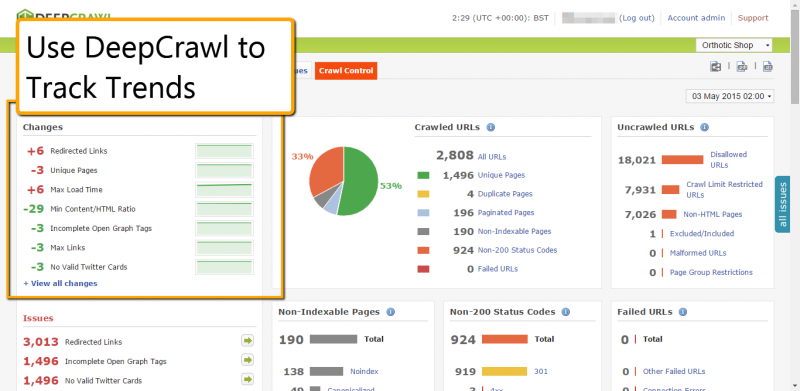
3. Monitor Trends Between Crawls
Tracking changes between crawls gives you powerful data to gauge site trends, get ahead of any emerging issues, and spot potential opportunities. DeepCrawl highlights these for you through the Added, Removed, and Missing reports. These are populated once a project has been re-crawled, and appear in every metric reported upon.
Once a follow-up crawl is finished, the new crawl shows your improved stats in green and potential trouble areas in red.
In addition to calculating the URLs which are relevant to a report, DeepCrawl also calculates the changes in URLs between crawls. If a URL appears in a report where it did not appear in the previous crawl, it will be included in the ‘Added report’. If the URL was included in the previous crawl, and is present in the current crawl, but not in this specific report, then it is reported within the ‘Removed report’. If the URL was in the previous crawl, but was not included in any report in the current crawl, it is included in the ‘Missing report’ (e.g. the URL may have been unlinked since last crawled).
![03-monitor-trends-between-crawls]()
4. Filters, filters, filters!
DeepCrawl reports are highly customisable. With well over 120 filtering options, you can really drill down into the data and isolate exactly what you are looking for – in relation to your specific SEO strategy and needs. Whether highlighting pages with high load times/GA bounce rates, missing social tags, broken JS/CSS, or low content: HTML ratio. You can even save your filters by creating tasks within reports, so the SEO issues that matter to you most will be flagged every time you recrawl, making the thorns in your side easy to monitor, as well as your progress!
![04-filters-filters-filters]()
5. Assign Tasks, Ease Workflows
After you’ve gone through a big audit, assigning and communicating all your to-do’s can be challenging for any site owner. By using the built-in task manager, a button on the top right of each area of your crawl, you can assign tasks as you go along to your team members, and give each task a priority. This system helps you track actions from your site audit in the Issues area, easing team workflows by showing you what is outstanding, what you’ve achieved so far etc. You can also add deadlines and mark projects as fixed, all from the same screen in the DeepCrawl projects platform. Collaborators receiving tasks do not need a DeepCrawl account themselves, as they’ll have access to the specific crawl report shared as guests.
![05-assign-issues-to-team-members]()
6. Share Read-Only Reports
This is one of my favourite options: sharing reports with C-levels and other decision makers without giving them access to other sensitive projects is easily doable with DeepCrawl. Generate an expiring URL to give them a high-level view of the site crawl as a whole or to kick out a PDF that focuses on a granular section, including content, indexation and validation. This also doubles up for sharing links externally when prospecting clients, especially if you’ve branded your DeepCrawl reports with your name and company logo.
![06-share-read-only-reports]()
7. DeepCrawl is now Responsive
With DeepCrawl’s new responsive design, crawl reports look great across devices. This means you can also set off crawls on the go, useful when setting off a quick site audit or pitch. Whilst you set off crawls from the palm of your hand you can also edit the crawls while you monitor them in real-time, in case you need to alter the speed or levels etc.
![07-deepcrawl-is-now-responsive]()
8. Brand your Crawl Reports
Are you a freelancer or an agency? In order to brand DeepCrawl reports with your business information/logo (or a client’s logo), and serve data to your team or client that is formatted to look as though it came directly from your shop, you can white-label them.
How To Do It:
- Go to Account Settings
- Select from Theme, Header colour, Menu colour, Logo and Custom proxy
- Make the report yours!
![08-brand-your-crawl-reports]()
Optimise your Crawl Budget
9. Crawl Your Site like Googlebot
Crawl your website just like search engine bots do. Getting a comprehensive report of every URL on your website is a mandatory component for regular maintenance. Crawl and compare your website, sitemap and landing pages to identify orphan pages, optimise your sitemaps and prioritise your workload.
![09-crawl-your-site-like-googlebot]()
10. Optimise your Indexation
DeepCrawl gives you the versatility to get high-level and granular views of indexation across your entire domain. Check if search engines can see your site’s most important pages from the Indexation report, which sits just under the Dashboard on the left hand navigation area. Investigate no-indexed pages to make sure you’re only blocking search engines from URLs when it’s absolutely necessary.
![10-optimise-your-indexation]()
11. Discover Potentially Non-indexable Pages
To stop you wasting crawl budget and/or identify wrongly canonicalised content, the Indexation reports show you a list of all no-indexed pages on your site, and gives you details about their meta-tags e.g. nofollowed, rel canonical, noindex etc. Pages with noindex directives in the robots meta tag, robots.txt or X-Robots-Tag in the header should be reviewed, as they can’t be indexed by search engines.
![11-non-indexable-pages]()
12. Discover Disallowed URLs
The Disallowed URLs report, nested under Uncrawled URLs within Indexation, contains all the URLs that were disallowed in the robots.txt file on the live site, or from a custom robots.txt file in the Advanced Settings. These URLs cannot be crawled by Googlebot, which prevents their appearance in search results, these should be reviewed to ensure that none of your valuable pages are being disallowed. It’s good to get an idea of which URLs may not be crawled by search engines.
![12-check-disallowed-urls-for-errors]()
13. Check Pagination
Pagination is crucial for large websites with lots of products or content, by making sure the right pages display for relevant categories on the site. You’ll find First Pages in a series in the pagination menu, you can also view unlinked paginated pages which is really useful for hunting down pages which might have rel=next and rel=prev implemented wrongly.
![13-hunt-down-pages-that-have-relnext-and-relprev-implemented-wrongly-copy]()
Understand your Technical Architecture
14. Introducing Unique Internal Links & Unique Broken Links
The Unique Internal Links report shows you the number of instances for all the anchor texts DeepCrawl finds in your crawl, so you can maximise your internal linking structure and spread your link juice out to rank for more terms! The links in this report can be analysed to understand for anchor text, as well as the status of the redirect target URL.
DeepCrawl’s Unique Broken Links report shows your site’s links with unique anchor text and target URL where the target URL returns a 4xx or 5xx status. Naturally, these links can result in poor UX and waste crawl budget, so they can be updated to a new target page or removed from the source page. This nifty new report is unique to DeepCrawl!
![14-introducing-unique-internal-links-_-unique-broken-links]()
15. Find Broken Links
Fixing 404 errors reduces the chance of users landing on broken pages and makes it easier on the crawlers, so they can find the most important content on your site more easily. Find 404s in DeepCrawl’s Non-200 Pages report. This gives you a full list of a 4xx errors on site at the time of audit, including their page title, URL, source code and the link on the page found to return a 404.
You’ll also find pages with 5xx errors, any unauthorised pages, non-301 redirects, 301 redirects, and uncategorised HTTP response codes, or pages returning a text/html content type and an HTTP response code which isn’t defined by W3C – these pages won’t be indexed by search engines and their body content will be ignored.
![15-find-broken-links]()
16. Fix Broken Links
Having too many broken links to internal and external resources on your website can lead to a bad user experience, as well as give the impression your website is out of date. Go to the Broken Pages report from the left hand menu to find them. Go fix them.
![16-fixing-broken-links]()
17. Check Redirects – Including Redirection Loops
Check the status of temporary and permanent redirects on site by checking the Non-200 Status report, where your redirects are nested. You can download 301 and 302 redirects or share a project link with team members to start the revision process
You can also find your Broken Redirects, Max Redirects and Redirect Loops. The Max Redirects report is defaulted to show pages that hop more than 4 times, this number can be customised on step 4 of your crawl set up in Report Settings, nested under Report Setup within the Advanced Settings.
The new Redirect Loop report contains URL chains which redirect back to themselves. These chains will result in infinite loops, causing errors in web browsers for users, and prevent crawling by search engines. In short, fixing them helps bots and, users, and prevent the loss of important authority. Once found you can update your redirect rules to prevent loops!

18. Verify Canonical Tags
Incorrect canonical tags can waste crawl budget and cause the bots to ignore parts of your site, leaving your site in danger, as search engines may have trouble correctly identifying your content. View canonicalised pages in your DeepCrawl audit from the Indexation report. The Non-Indexable report gives you the canonical’s location and page details (like hreflang, links in/out, any duplicate content/size, fetch time etc).
![18-see-all-canonical-tags-and-url-locations]()
19. Verify HREFLANG Tags
If your website is available in multiple languages, you need to validate the site’s HREFLANG tags. You can test HREFLANG tags through the validation tab in your universal crawl dashboard.
If you have HREFLANG tags in your sitemaps, be sure to include Web Crawl in your crawl set up, as this includes crawling your XML sitemaps. DeepCrawl reports on all HREFLANG combinations, working/broken, and/or unsupported links as well as pages without HREFLANG tags.
How To Do It:
- The Configuration report gives you an overview of HREFLANG implementation
- In the lower left menu, the HREFLANG section breaks down all the aspects of HREFLANG implementation into categorised pages
![19-verify-hreflang-tags]()
20. Optimise Image Tags
By using the custom extraction tool you can extract a list of images that don’t have alt tags across the site which can help you gain valuable rankings in Google Image Search.
How To Do It:
- Create custom extraction rules using Regular Expressions
- Hint: Try “/(<img(?!.*?alt=([‘”]).*?\2)[^>]*)(>)/” to catch images that have alt tag errors or don’t have alt tags altogether
- Paste your code into “Extraction Regex” from the Advanced Settings link on step 4 of your crawl set up
- Check your reports from your projects dashboard when the crawl completes. DeepCrawl gives two reports when using this setting: URLs that followed at least one rule from your entered syntax and URLs that returned no rule matches
![20-optimise-image-tags]()
21. Is Your Site Mobile-Ready?
Since “Mobilegeddon”, SEO’s have all become keenly aware of the constant growth of mobile usage around the world, where 70% of site traffic is from a mobile device. To optimise for the hands of the users holding those mobile devices, and the search engines connecting them to your site, you have to send mobile users content in the best way possible, and fast!
DeepCrawl’s new Mobile report shows you whether pages have any mobile configuration, and if so whether they are configured responsively, or dynamically. The Mobile report also shows you any desktop mobile configurations, mobile app links, and any discouraged viewport types.
![21-is-your-site-mobile-ready_]()
22. Migrating to HTTPS?
Google has been calling for “HTTPS everywhere” since 2014, and it has been considered a ranking signal. It goes without saying that sooner or later most sites may to switch to the secure protocol. By crawling both http/https, DeepCrawl’s HTTPS report will show you:
- HTTP resources on HTTPS pages
- Pages with HSTS
- HTTP pages with HSTS
- HTTP pages
- HTTPs pages
Highlighting any HTTP resources on HTTPS pages enables you to make sure your protocols are set up correctly, avoiding issues when search engines and browsers are identifying whether your site is secure or not. Equally, your users won’t see a red lock appear in the URL instead of a green lock, and won’t get a warning message from browsers saying proceed with caution, site insecure. Which is not exactly what people want to see when they are about to make a purchase, because when they see it, they probably won’t…
![22-migrating-to-https]()
23. Find Unlinked Pages driving Traffic
DeepCrawl really gives you a holistic picture of your site’s architecture. You can incorporate up to 5 sources into each crawl. By combining a website crawl with analytics you’ll get a detailed gap analysis, and find URLs which have generated traffic but aren’t linked – also known as orphans – will be highlighted for you.
Pro tip: even more so if you add backlinks and lists to your crawl too! You can link your Google Analytics account and sync 7 or 30 days of data, or you can manually upload up to 6 months worth of GA or any other analytics (like Omniture) for that matter. This way you can work on your linking structure, and optimise pages that would otherwise be missed opportunities.
![23-find-unlinkedin-pages-driving-traffic]()
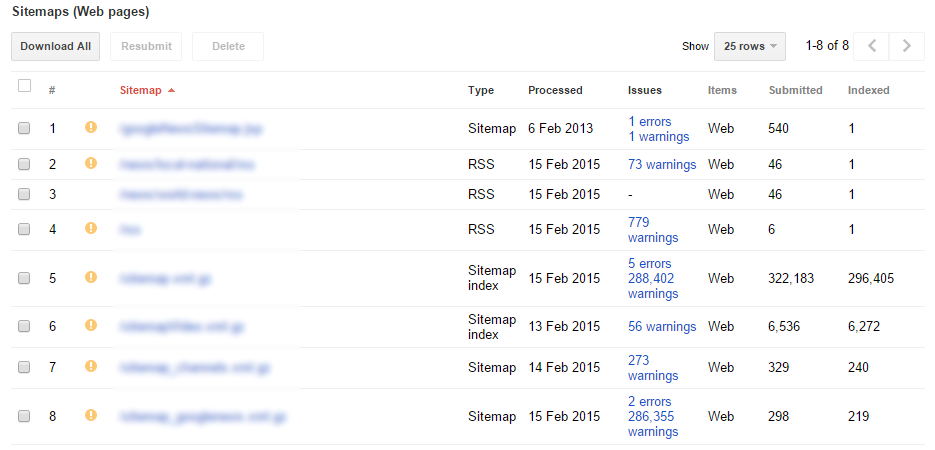
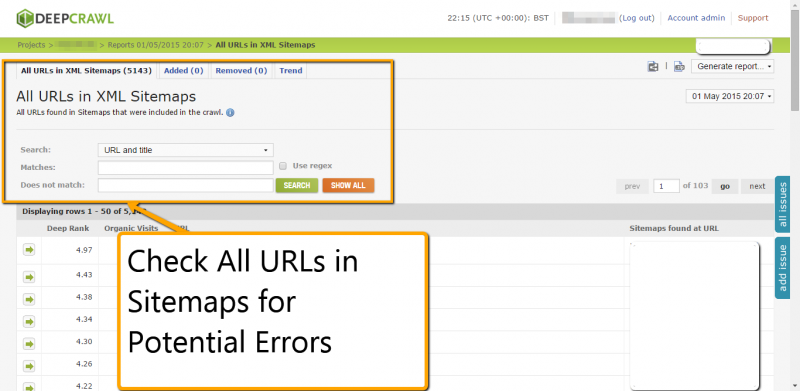
24. Sitemap Optimisation
You can opt to manually add sitemaps into your crawl and/or let DeepCrawl automatically find them for you. It’s worth noting that if DeepCrawl does not find them, then it’s likely that search engines won’t either! By including sitemaps into your website crawl, DeepCrawl identifies the pages that either aren’t linked internally or are missing from sitemaps.
By including analytics in the crawl you can also see which of these generate entry visits, revealing gaps in the sitemaps. Moreover, shedding light on your internal linking structure by highlighting where they don’t match up, as you’ll see the specific URLs that are found in the sitemaps but aren’t linked, likewise those that are linked but are not found in your sitemaps.
Performing a gap analysis to optimise your sitemaps with DeepCrawl enables you to visualise your site’s structure from multiple angles, and find all of your potential areas and opportunities for improvement. TIP: You can also use the tool as an XML sitemaps generator.
![24-sitemap-optimisation]()
25. Control Crawl Speed
You can crawl at rates as fast as your hosting environment can handle, which should be used with caution to avoid accidentally taking down a site. DeepCrawl boasts one of the most nimble audit spiders available for online marketers working with enterprise level domains.
Whilst appreciating the need for speed, accuracy is what’s most important! That said, you can change crawl speeds by URLs crawled per second when setting up, or even during a live crawl. Speeds range from 0-50 URLs crawled per second.
![25-control-crawl-speed]()
Is your Content being found?
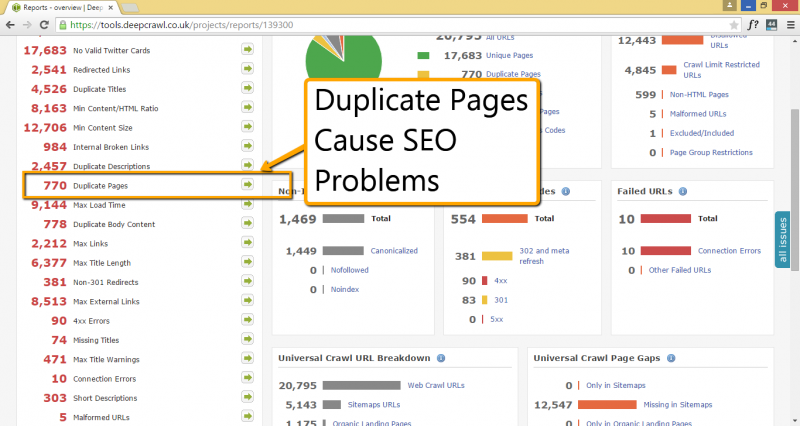
26. Identifying Duplicate Content
Duplicate content is an ongoing issue for search engines and users alike, but can be difficult to hunt down. Especially on really, really large sites. But, these troublesome pages are easily identified using DeepCrawl.
Amongst DeepCrawl’s duplicate reporting features, lies the Duplicate Body Content report. Unlike the previous version of DeepCrawl, the new DeepCrawl doesn’t require the user to adjust sensitivity. All duplicate content is flagged, to help avoid repeated content that can confuse search engines, make original sources fail to rank, and aren’t really giving your readership added value.
Finding Duplicate Titles, Descriptions, Body Content, and URLs with DeepCrawl is an effortless time-saver.
![26-identifying-duplicate-content]()
27. Identify Duplicate Pages, Clusters, Primary Duplicates & Introducing True Uniques
Clicking into Duplicate Pages from the dashboard gives you a list of all the duplicates found in your crawl, which you can easily download or share. DeepCrawl now also gives you a list of Duplicate Clusters so you can look at groups of duplicates to try find the cause/pattern of these authority-draining pages.
There is also a new report entitled True Uniques. These pages have no duplicates coming off them in any way shape or form, are the most likely to be indexed, and naturally are very important pages in your site.
Primary Duplicates have duplicates coming off them – as the name implies – but have the highest internal link weight from each set of duplicated pages. Though signals like traffic and backlinks need be reviewed to assess the most appropriate primary URL, these pages should be analysed – as they are the most likely to be indexed.
Duplicate Clusters are pages sharing an identical title and near identical content with another page found in the same crawl. Duplicate pages often dilute authority signals and social shares, affecting potential performance and reducing crawl efficiency on your site. You can optimise clusters of these pages, by removing internal links to their URLs and redirecting duplicate URLs to the primary URL, or adding canonical tags to another one.
How To Do It:
- Click “Add Project” from your main dashboard
- Under the crawl depth setting tell DeepCrawl to scan your website at all its levels
- Once the crawl has finished, review your site’s duplicate pages from the “issues” list on your main dashboard or search for ‘duplicate’ in the left nav search bar
![27-identify-duplicate-pages-clusters-primary-duplicates-_-introducing-true-uniques]()
28. Sniff Out Troublesome Body Content
Troublesome content impacts UX and causes negative behavioral signals like bouncing back to the search results. Review your page-level content after a web crawl by checking out empty or thin pages, and digging into duplication. DeepCrawl gives you a scalpel’s precision in pinpointing the problems right down to individual landing pages, which enables you to direct your team precisely to the source of the problem.
How To Do It:
- Click on the Body Content report in the left hand menu
- You can also select individual issues from the main dashboard
- Assign tasks using the task manager or share with your team
![28-sniff-out-troublesome-body-content]()
29. Check for Thin Content
Clean, efficient code leads to fast loading sites – a big advantage in search engines and for users. Search engines tend to avoid serving pages that have thin content and extensive HTML in organic listings. Investigate these pages easily from the Thin Pages area nested within the Content report.
![29-find-pages-with-bad-html_content-ratios]()
30. Avoid Panda, Manage Thin Content
In a post-Panda world it’s always good to keep an eye on any potentially thin content which can negatively impact your rankings. DeepCrawl has a section dedicated to thin and empty pages in the body content reports.
The Thin Pages report will show all of your pages with less than the minimum to content size specified in Advanced Settings > Report Settings (these settings are defaulted at 3 kb, you can also choose to customise them). Empty pages are all your indexable pages with less content than the Content Size setting specified (default set at 0.5 kilobytes) in Advanced Settings > Report Settings.
How To Do It:
- Typing content in the main menu will give you the body content report
- Clicking on the list will give you a list of pages you can download or share
![30-avoid-a-thin-content-penalty-now]()
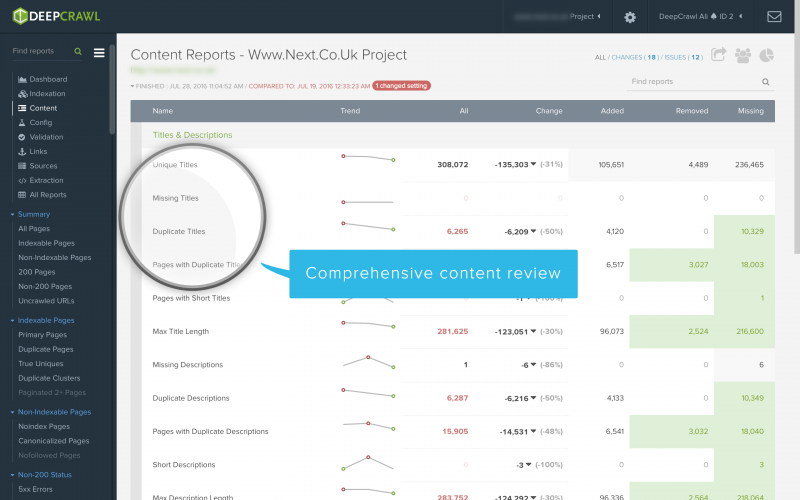
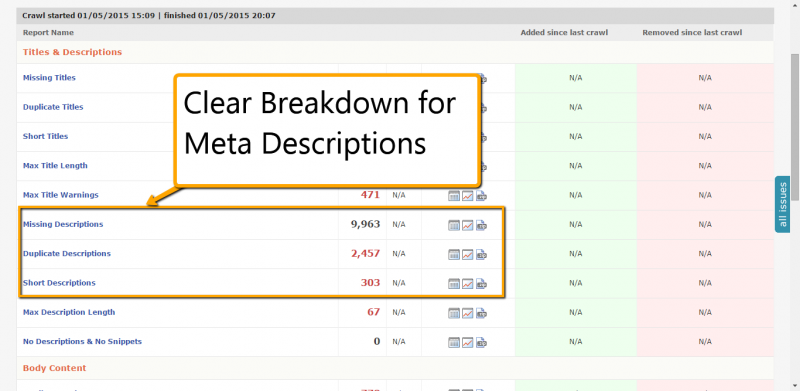
31. Optimise Page Titles & Meta Descriptions
Page titles and meta descriptions are often the first point of contact for users to your site coming from the search results, well written and unique descriptions can have a big impact on click through rates and user experience. Through the Content report, DeepCrawl gives you an accurate count of duplicate, missing and short meta descriptions and titles.
![31-optimise-page-title-_-meta-description]()
32. Clean Up Page Headers
Cluttered page headers can impair the click through rate if users’ expectations are not being managed well. CTRs can vary by wide margins, which makes it difficult to chart the most effective path to conversion.
If you suspect your page headers are cluttered by running a crawl with Google Analytics data, you can assess key SEO landing pages, and gain deeper insights, by combining crawl data with powerful analytics data including bounce rate, time on page, and load times.
![32-clean-up-page-headers]()
Other nuggets that DeepCrawl gives
33. How Does Your Site Compare to Competitors?
Set up a crawl using the “Stealth Crawl” feature to perform an undercover analysis of your competitor’s site, without them ever noticing. Stealth Crawl randomises IPs, user agents with delays between requests – making it virtually indistinguishable from regular traffic. Analyse their site architecture and see how your site stacks up in comparison, insodoing discovering areas for improvement.
How To Do It:
- Go to the Advanced Settings in step 4 of your crawl setup and select and tick Stealth Mode Crawl nested under the Spider Settings
![33-how-does-your-site-compare-to-competitors_]()
34. Test Domain Migration
There’s always issues with newly migrated websites which usually generate page display errors and the site going down. By checking status codes post-migration in DeepCrawl you can keep an eye on any unexpected server-side issues as you crawl.
In the Non-200 Pages report you can see the total number of non-200 status codes, including 5xx and 4xx errors that DeepCrawl detected during the platform’s most recent crawl.
![34-test-domain-migration]()
35. Test Individual URLs
Getting a granular view over thousands of pages can be difficult, but DeepCrawl makes the process digestible with an elegant Pages Breakdown pie chart on the dashboard that can be filtered and downloaded for your needs. The pie chart (along with all graphs and reports) can be downloaded in the format of your choice, whether CSV/PNG/PDF etc.
View Primary Pages by clicking the link of the same name (primary pages) in your dashboard overview. From here, you can see a detailed breakdown of each and every unique and indexable URL of up to 200 metrics, including DeepRank (an internal ranking system), clicks in, load time, content/HTML ratio, social tags, mobile-optimization (or lack thereof!), pagination and more.
![35-test-individual-urls]()
36. Make Landing Pages Awesome and Improve UX
To help improve conversion and engagement, use DeepCrawl metrics to optimise page-level factors like compelling content and pagination, which are essential parts of your site’s marketing funnel that assist in turning visitors into customers.
You can find content that is missing key parts through the page content reports to help engage visitors faster, deliver your site’s message in a clearer way and increasing chances for conversions and exceeding user expectations.
![36-make-landing-pages-awesome-and-improve-ux]()
37. Optimise your Social Tags
To increase shares on Facebook (Open Graph) and Twitter and get the most out of your content and outreach activities, you need to make sure your Twitter Cards and Open Graph tags are set up and set up correctly.
Within DeepCrawl’s Social Tagging report you will see pages with or without social tags, whether those that do are valid, and OG:URL Canonical Mismatch or, pages where the Open Graph URL is different to the Canonical URL. These should be identical, otherwise shares and likes might not be aggregated for your chosen URL in your Open Graph data but be spread across your URL variations.
![37-optimise-your-social-tags]()
Want Customised Crawls?
38. Schedule Crawls
You can schedule crawls using DeepCrawl to automatically run them in the future and adjust their frequency and start time. This feature can also be used to avoid times of heavy server load. Schedules range from every hour to every quarter.
How To Do It:
- In step 4 of your crawl set up click on Schedule crawl
![38-schedule-crawls]()
39. Run Multiple Crawls at Once
You can crawl multiple sites (20 at any given time) really quickly as DeepCrawl is cloud-based, spanning millions of URLs at once while still being able to use your computer to evaluate other reports. Hence with DeepCrawl you can perform your Pitch, SEO Audit and your Competitor Analysis at the same time.
![39-run-multiple-crawls-at-once]()
40. Improve Your Crawls with (Google) Analytics Data
By authenticating your Google Analytics accounts into DeepCrawl you can understand the combined SEO and analytics performance of key pages in your site. By overlaying organic traffic and total visits on your individual pages you can prioritise changes based on page performance.
How To Do It:
- On step 2 of your crawl set up, go to Analytics, click add Google account
- Enter your Google Analytics name and password to sync your data permissions within the DeepCrawl
- Click the profile you want to share for the DeepCrawl project
- DeepCrawl will sync your last 7 or 30 days of data (your choice), or you can choose to upload up to 6 months worth of data by uploading the data as a CSV file, whether from Google Analytics or Omniture or any providers
![40-improve-your-crawls-with-google-analytics-data]()
41. Upload Backlinks and URLs
Identify your best linked sites by uploading backlinks from Google Search Console, or lists of URLs from other sources to help you track the SEO performance of the most externally linked content on your site.
![41-upload-backlinks-and-urls]()
42. Restrict Crawls
Restrict crawls for any site using DeepCrawl’s max URL setting, using the exclude URL list or the page grouping feature which lets you restrict pages based on their URL patterns. With page grouping you can chose to crawl say 10% of a particular folder or of each folder on your site if you’re looking for a quick snapshot. Once you’ve re-crawled (so long as you keep the same page grouping settings), DeepCrawl will recrawl the same 10% so you can monitor changes.
Aside from Include/Exclude Only rules you can restrict your crawls by Starting URLs and by limited the depth and/or number of URLs you’d like to crawl on your given site.
How to Do It:
- In Advanced Settings nested in step 4 of your crawl set up click “Included / Excluded URLs” or “Page Grouping” and/or “Start URLs”
![42-restrict-crawls]()
43. Check Implementation of Structured Data
Access Google’s own Structured Data Testing Tool to validate Schema.org markup by adding a line or two of code to your audit through DeepCrawl’s Custom Extraction. This tool helps you see how your rich snippets may appear in search results, where errors in your markup prevent it from being displayed, and whether or not Google interprets your code, including rel=publisher and product reviews, correctly.
How To Do It:
- In Advanced Settings of step 4 of your crawl set up
- Click on “custom extraction”
- Add the Custom Extraction code found here to get DeepCrawl to recognise Schema markup tags and add the particular line of code you want for your crawl: ratings, reviews, person, breadcrumbs, etc
itemtype=”http://schema.org/([^”]*)
itemprop=”([^”]*)
(itemprop=”breadcrumb”)
(itemtype=”http://schema.org/Review”)
![43-check-implementation-of-structured-data]()
44. Using DeepCrawl as a Scraper
Add custom rules to your website audit with DeepCrawl’s Custom Extraction tool. You can tell the crawler to perform a wide array of tasks, including paying more attention to social tags, finding URLs that match a certain criteria, verifying App Indexing deeplinks, or targeting an analytics tracking code to validate product information across category pages.
For more information about Custom Extraction syntax and coding, check out this tutorial published by the DeepCrawl team.
How To Do It:
- Enter your Regular Expressions syntax into the Extraction Regex box in the advanced settings of step 4 of your crawl
- View your results by checking the Custom Extraction tab in your project’s crawl dashboard or at the bottom of the navigation menu
![44-using-deepcrawl-as-a-scraper]()
45. Track Migration Changes
Migrations happen for a lot of reasons, and are generally challenging. To aid developers, SEOs and decision makers from the business coming together and trying to minimise risks, use DeepCrawl to compare staging and production environments in a single crawl to spot any issues before you migrate and make sure no-one missed their assignments, and ensure the migration goes smoothly.
For site migrations and/or redesigns, testing changes before going live can show you whether your redirects are correctly set up, whether you’re disallowing/no-indexing valuable pages in your robots.txt etc., being careful does pay off!
![45-track-migration-changes]()
46. Crawl as Googlebot or Your Own User Agent
If your site auditor can’t crawl your pages as a search engine bot, then you have no chance of seeing the site through the search engine’s eyes. DeepCrawl can also mimic spiders from other search engines, social networks and browsers. Select your user agent in the advanced settings when setting up or editing your crawl.
Your options are:
- Googlebot (7 different options)
- Applebot
- Bingbot
- Bingbot mobile
- Chrome
- Facebook
- Firefox
- Generic
- Internet Explorer 6 & 8
- iPhone
- DeepCrawl
- Custom User Agent
![46-crawl-as-googlebot-or-your-own-user-agent]()
Last but not least
This top 46 list is by no means complete. In fact, there are many more possibilities to utilise DeepCrawl for enhancing site performance and the tool undergoes constant improvements. This list is a starting point to understanding your website as search engines do and making improvements for users and search engines alike.
DeepCrawl is a very powerful tool and conclusions drawn using the data it provides must be based on experience and expertise. If applied to its full effect DeepCrawl can bring an online business to the next level and significantly contribute to user expectations management, brand building and most importantly driving conversions.
What are your favourite DeepCrawl features? Your opinion matters, share it in the comments section below.
Post from Fili Wiese












 In my previous post for State of Digital I wrote about my
In my previous post for State of Digital I wrote about my 






























 Page-level elements, including H1 tags, compelling content, and proper pagination, are essential parts of your site’s marketing funnel that helps turn visitors into leads. Use DeepCrawl’s metrics to help improve engagement and conversion. Find content that is missing key parts through the “unique pages” tab, including H1s, H2s, sitemap inclusion, and social markup, to help them engage visitors faster, deliver your site’s message in a clearer fashion, and increase chances for conversions and exceeding user expectations.
Page-level elements, including H1 tags, compelling content, and proper pagination, are essential parts of your site’s marketing funnel that helps turn visitors into leads. Use DeepCrawl’s metrics to help improve engagement and conversion. Find content that is missing key parts through the “unique pages” tab, including H1s, H2s, sitemap inclusion, and social markup, to help them engage visitors faster, deliver your site’s message in a clearer fashion, and increase chances for conversions and exceeding user expectations.







 Use DeepCrawl’s report scheduling feature to auto-run future crawls, including their frequency, start date, and even time of day. This feature can also be used to avoid sensitive and busy server times or have monthly reported emailed directly to you or your team.
Use DeepCrawl’s report scheduling feature to auto-run future crawls, including their frequency, start date, and even time of day. This feature can also be used to avoid sensitive and busy server times or have monthly reported emailed directly to you or your team.